# Install dependencies.
%pip install tiktokenTokenization
What is Tokenization?
Tokenization is a fundamental process in Natural Language Processing (NLP) that involves breaking text into smaller units called “tokens.” These tokens serve as the basic building blocks that machine learning models can process.
For Large Language Models (LLMs), tokenization is a critical first step that converts human-readable text into numerical formats the model can understand. When you send a prompt to an LLM such as GPT or Claude, the model doesn’t directly read your text - it processes sequences of tokens that represent your text.
There are several approaches to tokenization:
- Word tokenization: Splitting text by words (separated by spaces or punctuation)
- Subword tokenization: Breaking words into meaningful subunits (most common in modern LLMs)
- Character tokenization: Dividing text into individual characters
Tokenization presents various challenges, including handling punctuation, contractions, compound words, and rare words. The choice of tokenization method significantly impacts an LLM’s performance, vocabulary size, and ability to handle different languages.
This notebook explores tokenization techniques based on Sebastian Raschka’s book (Chapter 2), implementing various tokenization approaches and analyzing their effects.
Tokenization Process
Borrowed from Manning’s Live Books

Acknowledgment
All concepts, architectures, and implementation approaches are credited to Sebastian Raschka’s work. This repository serves as my personal implementation and notes while working through the book’s content.
Resources
import re
from typing import Dict, List
import urllib.request
from importlib.metadata import version
import tiktoken# Verify library versions.
print("tiktoken version:", version("tiktoken")) # expected: 0.7.0Fetch sample data
# Download sample data to a text file.
local_filename = "data/the_verdict.txt"
url = (
"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/"
"the-verdict.txt"
)
urllib.request.urlretrieve(url, local_filename)
# Read the text file into a string.
with open(local_filename, "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))Prepare text for tokenization
# Split on whitespace only.
text = raw_text[:150]
print(text)
print(re.split(r"(\s)", text))
# Split on whitespace and punctuation.
# NOTE: This regular expression combines two or-conditions:
# 1. A comma or period (e.g., "hello," or "world.")
# 2. A whitespace character (e.g., "hello world")
# 3. A dash (e.g., "hello-world")
result = re.split(r"([,.-]|\s)", text)
print(result)
# Handle a wider range of punctuation.
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
print(result)
# Remove whitespace from the result.
result = [item for item in result if item.strip()]
print(result)
def preprocess_text(text):
# Split on whitespace and punctuation.
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
return [item for item in result if item.strip()]
# Preprocess the text.
preprocessed_text = preprocess_text(raw_text)
print(f"Raw text: {len(raw_text)} characters")
print(f"Preprocessed text: {len(preprocessed_text)} tokens")Create a vocabulary of unique tokens
# Compute the set of unique tokens and sort alphabetically.
all_words = sorted(set(preprocessed_text))
vocab_size = len(all_words)
print(f"Vocabulary size: {vocab_size} unique tokens")
# Create a lookup table that maps tokens to integers.
token_to_id = {token: integer for integer, token in enumerate(all_words)}
id_to_token = {integer: token for token, integer in token_to_id.items()}
for i, item in enumerate(token_to_id.items()):
print(item)
if i >= 50:
breakV1: A simple tokenizer class
class SimpleTokenizerV1:
def __init__(self, vocab: Dict[str, int]):
self.str_to_int = vocab
self.int_to_str = {integer: token for token, integer in vocab.items()}
@staticmethod
def preprocess(text: str) -> List[str]:
"""Split on whitespace and punctuation."""
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
return [item for item in result if item.strip()]
def encode(self, text: str) -> List[int]:
"""Preprocess the text and convert tokens to integers."""
tokens = SimpleTokenizerV1.preprocess(text)
return [self.str_to_int[token] for token in tokens]
def decode(self, ids: List[int]) -> str:
"""Convert integers back to tokens."""
# Convert integers back to tokens and concatenate them.
text = " ".join([self.int_to_str[id] for id in ids])
# Removes spaces before the specified punctuation (i.e. before commas, periods, etc.).
text = re.sub(r'\s+([,.?!"()\'])', r"\1", text)
return text
# Test the tokenizer.
tokenizer = SimpleTokenizerV1(vocab=token_to_id)
text = (
""""It's the last he painted, you know, Mrs. Gisburn said with pardonable pride."""
)
ids = tokenizer.encode(text)
print(ids)
print(tokenizer.decode(ids))V2: A more advanced tokenizer
# Add new special tokens:
# - <|endoftext|>
# - <|unk|>
all_tokens = sorted(list(set(preprocessed_text)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token: integer for integer, token in enumerate(all_tokens)}
print(len(vocab.items()))class SimpleTokenizerV2:
def __init__(self, vocab: Dict[str, int]):
self.str_to_int = vocab
self.int_to_str = {integer: token for token, integer in vocab.items()}
@staticmethod
def preprocess(text: str) -> List[str]:
"""Split on whitespace and punctuation."""
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
return [item for item in result if item.strip()]
def encode(self, text: str) -> List[int]:
"""Preprocess the text and convert tokens to integers."""
# Preprocess the text.
tokens = SimpleTokenizerV1.preprocess(text)
# Handle unknown tokens.
tokens = [token if token in self.str_to_int else "<|unk|>" for token in tokens]
# Convert tokens to integers (i.e. token IDs).
return [self.str_to_int[token] for token in tokens]
def decode(self, ids: List[int]) -> str:
"""Convert integers back to tokens."""
# Convert integers back to tokens and concatenate them.
text = " ".join([self.int_to_str[id] for id in ids])
# Removes spaces before the specified punctuation (i.e. before commas, periods, etc.).
text = re.sub(r'\s+([,.?!"()\'])', r"\1", text)
return text# Test the new tokenizer.
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)
tokenizer = SimpleTokenizerV2(vocab)
print(tokenizer.encode(text))
print(tokenizer.decode(tokenizer.encode(text)))V3: Using tiktoken
Notes: 1. The endoftext token has a fairly large ID (50256) given the large vocabulary size for GPT-2. 2. The BPE tokenizer correctly encodes/decodes unknown words.
The Byte Pair Encoding (BPE) algorithm is explained in detail here
Algorithm explained via a simple example
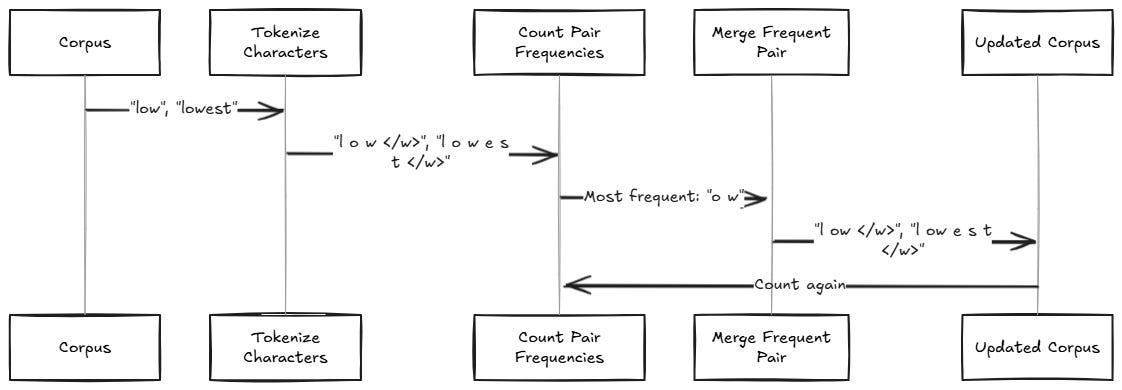
Example of BPE tokenization for unknown words
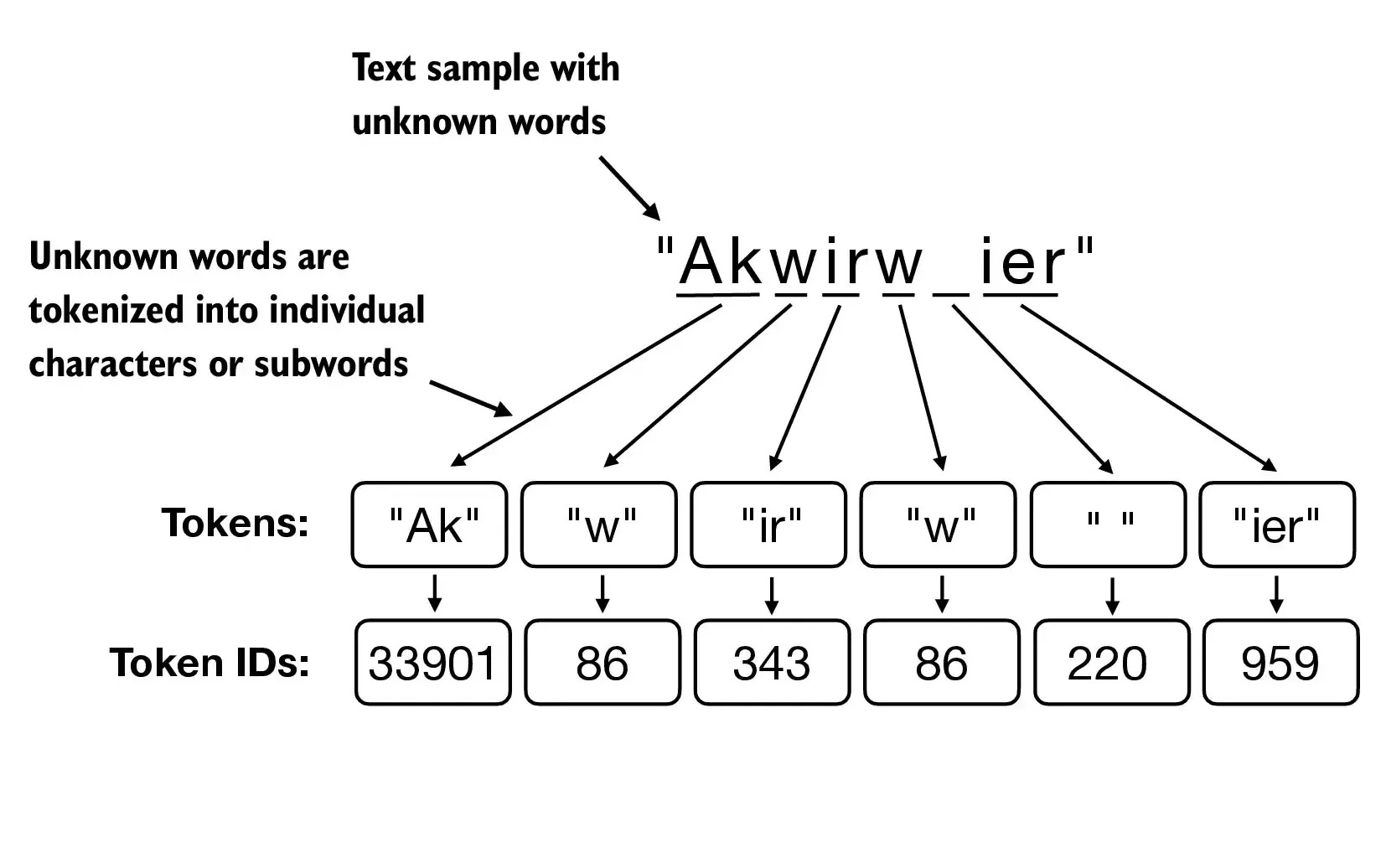
tokenizer = tiktoken.get_encoding("gpt2")
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
print(text)
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
strings = tokenizer.decode(integers)
print(strings)tokenizer.decode(tokenizer.encode("Akwirw ier"))